从 Prompt 到 Ralph Loop:一文了解 AI 的循环编程
如果你用过 AI 写代码,大概率经历过这样的循环:
写一个 prompt → AI 回答不对
改 prompt → 再问一次
再改 → 再问
大多数时候,问题不是 AI 不够聪明,而是这种 “人不断介入” 的方式,本身就很低效。
有人干脆反过来想了一下:如果让 AI 自己一直试,直到成功,会发生什么?
这个想法,被起了一个听起来很不像技术的名字:Ralph Wiggum。
Ralph 的由来
提出 Ralph 的作者是 Geoffrey Huntley,一位住在澳大利亚乡下的软件开发者。他一边做开源和软件工作,一边处理放羊等农场日常事务。
Ralph Wiggum(翻译过来是”拉尔夫·威格姆”)出自动画《辛普森一家》。在剧中,Ralph 是一个天真、常常说错话、但一直很认真的角色。用他的名字,其实是带点自嘲意味的:
哪怕我不聪明、经常失败,但我会一直重试。
这正好贴合很多 LLM / Agent 开发的真实状态。
Ralph Wiggum Method 的原理
按照作者的话讲:
Ralph is a Bash loop
原理很简单,没有复杂架构、没有 fancy 的 agent 设计:
a simple while loop that repeatedly feeds an AI agent a prompt until completion.
就是:用一个无限循环,不断把 prompt 喂给 AI,直到任务完成。
作者也给出了一个十分简单的例子:
1
2
3
while :; do
cat PROMPT.md | claude-code
done
这段代码会不断地将一个 prompt 文件喂给一个 AI 编码 Agent(例如 Claude Code),让模型不断执行、失败、再执行,直到满足某种完成条件为止。
Huntley 并没有把 Ralph 描述成某个具体的软件工具,而是一种工作流程与方法论。在他的博客中,他强调:
- Ralph 是一种”技术”(technique),不是框架或库
- 它的本质是通过不断循环让 AI 自我迭代
- 这种方法在一个不确定的世界里,“可预测的失败”比”不可预测的成功”更有价值
Claude Code 引入
当这个简单的循环想法传播开来后,Anthropic 将其整合进了自家的 AI 编程平台 Claude Code,以插件形式提供了一套更可靠、更结构化的循环执行机制。
这个官方实现就叫 Ralph Wiggum plugin:
至此,有两种版本的 Ralph:
① Huntley 原始版本(社区脚本)
- 主要特征是无限循环反馈模式
- 更适合”开放式探索、多次迭代、输出不受过度约束的代码”
② Anthropic 版本
- 引入了 Stop Hook 机制,用于在内部拦截退出尝试
- 需要提前定义好”完成承诺”
- 插件版本比原始 Bash 循环更安全、结构更严谨
Stop Hook:Ralph Loop 的核心机制
在 Claude Code 中,官方版本的 Ralph 引入了 Stop Hook 机制:
- 你给 Claude 一个任务,以及一个 “完成承诺”(Completion Promise),例如
<promise>COMPLETE</promise> - Claude 开始执行任务,并在认为自己完成时尝试退出
- 如果代理尝试在未提供该特定词(例如
"COMPLETE")的情况下退出,Hook 会阻止退出。然后,它会将原始 prompt 以及当前文件状态重新送回 Claude
这就形成了一个 “自反馈循环”:Claude 会看到自己之前的工作、阅读错误日志或 git 历史,然后重新尝试。
Pocock 将这种机制描述为从 “瀑布式(Waterfall)规划” 向真正的 “敏捷(Agile)AI” 的转变:
与其强迫 AI 按照脆弱的多步计划执行,Ralph 让代理能够 直接拿到一个任务票(ticket)去完成,然后再去寻找下一个任务。
Claude Code 里的 Ralph
在 Claude Code 里通过插件形式来使用 Ralph。
安装官方提供的版本插件:
1
/plugin install ralph-loop@claude-plugins-official
接着启动一个循环:
1
/ralph-loop:ralph-loop "<prompt>" --completion-promise "text" --max-iterations n
参数配置如下:
<prompt>:让 Claude 完成的任务 prompt--completion-promise "<text>":指定循环结束的标记词,例如DONE或COMPLETE--max-iterations <n>:设置最大迭代次数(推荐设置以避免无限循环)
常用命令如下:
/ralph-loop:ralph-loop "<prompt>":启动 Ralph 循环/ralph-loop:cancel-ralph:取消当前正在进行的循环/ralph-loop:help:显示 Ralph Wiggum 技术及命令说明
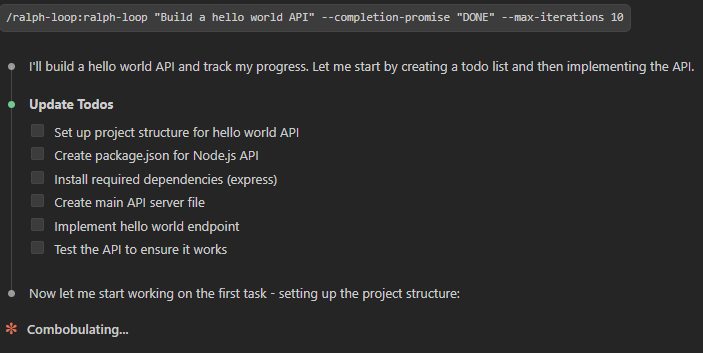
我们尝试例子如下,开启一个简单任务:
1
/ralph-loop:ralph-loop "Build a hello world API" --completion-promise "DONE" --max-iterations 10
如下截图:
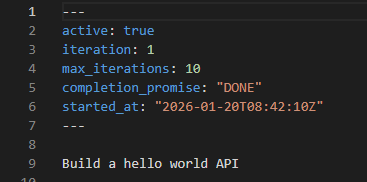
同时可以看到 Claude 会生成一个 local.md:
接着,Claude 会进行迭代,Stop Hook 阻止退出,进度不断累积,过程如下:
- Work on the task
- Try to exit
- Stop hook blocks exit
- Same prompt fed back
- Repeat until DONE
Best Practices
要让 Ralph Loop 真正发挥作用,最关键的不是模型本身,而是 提示词(Prompt)的设计。
Claude 的表现高度依赖于提示的清晰程度和结构。官方给出了几条实践建议:
1. Clear Completion Criteria(清晰的完成标准)
循环的成功依赖于 明确的完成条件。模糊的提示容易让 Claude 不断尝试却无法停下。
不好的示例:
1
Build a todo API and make it good.
好的示例:
1
2
3
4
5
6
7
8
Build a REST API for todos.
When complete:
- All CRUD endpoints working
- Input validation in place
- Tests passing (coverage > 80%)
- README with API docs
- Output: <promise>COMPLETE</promise>
2. Incremental Goals(分阶段目标)
对复杂任务,将目标拆解成阶段能让循环更容易完成,也让每轮迭代更加可控。
不好的示例:
1
Create a complete e-commerce platform.
好的示例:
1
2
3
4
5
Phase 1: User authentication (JWT, tests)
Phase 2: Product catalog (list/search, tests)
Phase 3: Shopping cart (add/remove, tests)
Output <promise>COMPLETE</promise> when all phases done.
3. Self-Correction Pattern(自我修正模式)
为了充分发挥循环迭代的优势,可以在提示中明确 自我修正步骤,让 Claude 每轮都能参考上一次的输出和错误进行改进。
不好的示例:
1
Write code for feature X.
好的示例:
1
2
3
4
5
6
7
8
Implement feature X following TDD:
1. Write failing tests
2. Implement feature
3. Run tests
4. If any fail, debug and fix
5. Refactor if needed
6. Repeat until all green
7. Output: <promise>COMPLETE</promise>
4. Escape Hatches(退出保护)
- 始终使用
--max-iterations:防止循环无限执行在不可能完成的任务上 - 包括卡住情况的处理说明:记录在达到 N 次失败迭代后应采取的措施
- 注意:
--completion-promise使用精确字符串匹配,建议将--max-iterations作为主要的安全控制
何时使用 Ralph
适合使用的情况
- 明确完成标准的任务:任务的成功条件清晰,例如通过测试或自动验证,Ralph 循环能高效完成
- 需要循环迭代才能完成的任务:当任务必须反复尝试才能达到目标时,Ralph 的自指循环能持续推进
- Greenfield 项目:对于从头开始的新项目,Ralph 可以自动生成和迭代代码
- 可以自动验证的任务:有测试、lint 或其他自动检查机制的任务,适合使用 Ralph 循环
- Overnight / weekend automated development:Ralph 适合夜间或周末无人干预的自动化开发,让 AI 自行迭代完成任务
不适合使用的情况
- 需要人工判断或设计决策的任务:任务中必须依赖人工判断或决策时,不适合使用 Ralph
- 一次性操作:不需要循环迭代、只需执行一次的任务,不适合使用 Ralph
- 成功标准不清晰的任务:若任务的完成条件不明确,循环可能无法正确结束
- 生产环境中的调试任务:调试类任务需要针对性操作,而非自动循环
- Tasks requiring external approvals or human-in-the-loop:需要外部审批或人工干预的流程,Ralph 的自动循环无法满足
很明显,由于循环会重复执行 prompt,每轮迭代都会消耗 token 和计算能力。对长 prompt 或大规模任务,成本可能显著增加,建议通过
--max-iterations限制循环次数,避免无限循环造成资源浪费。
Ralph 的哲学
Ralph 的哲学可以概括为:
“在不可确定的世界里,用确定性的失败去推动进步。”
AI 很少能一次输出完美结果,每一次尝试都有可能失败。
在 Ralph Loop 中,这些失败不是浪费,而是有价值的反馈:
- Stop Hook 与自反馈循环让 AI 可以参考自己的历史输出和错误日志
- 每一次失败都是一次迭代冲刺,让 AI 能够自我修正并逐步逼近目标
与其期待一次成功的 Prompt,不如通过一次又一次的失败,让 AI 从中学习,逐步改进结果。
正如敏捷开发理念,每一次失败都推动任务向完成靠近,使自动化开发在不确定的世界中仍然稳步前进。