了解下吴恩达的《AI Prompting for Everyone》
了解下吴恩达的《AI Prompting for Everyone》
分享下最近了解的一门课程,来自吴恩达在 DeepLearning.AI 上的AI Prompting for Everyone,下面按主题重新整理了下
AI 的知识来自哪里
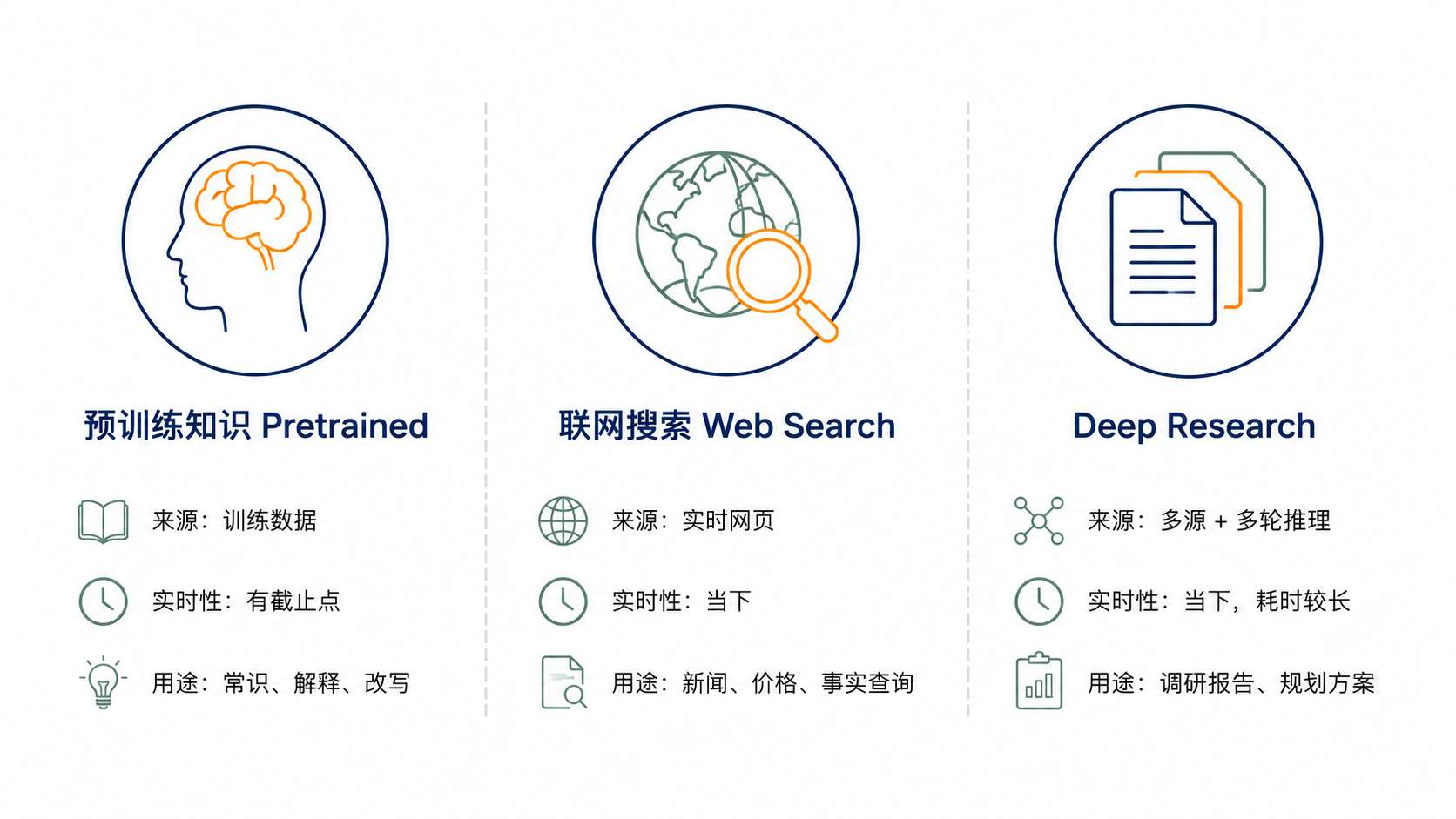
课程前几节把模型回答时的知识来源拆成了三种:
- 预训练知识:模型训练时读过的内容,有训练数据的时间截止点;超出截止点的内容它默认不知道,可能会编(hallucinate)。
- Web Search:联网搜索结果会被塞回上下文再生成回答;上限取决于搜索结果本身的质量。
- Deep Research:针对复杂问题,模型会跑多轮搜索加多轮推理,产出带引用的报告。课程把它作为一种与普通问答并列的工作模式。
提问之前判断当前问题该走哪条路:
- 常识问题用预训练
- 实时事实用联网
- 调研类问题用 Deep Research
上下文(Context)

课程把上下文拆为四部分:
- 模型的预训练知识
- 系统指令(system prompt)
- 当前这轮提问
- 当前对话历史和你上传的附件
几个直接结论:
- 上下文窗口有上限,超出后较早的内容会被截断或被忽略。
- 不同对话窗口之间没有共享记忆,新窗口对之前的对话一无所知。
- 长期使用的背景信息建议沉到文档里,每次对话开始时再贴一次,不要依赖历史记录。
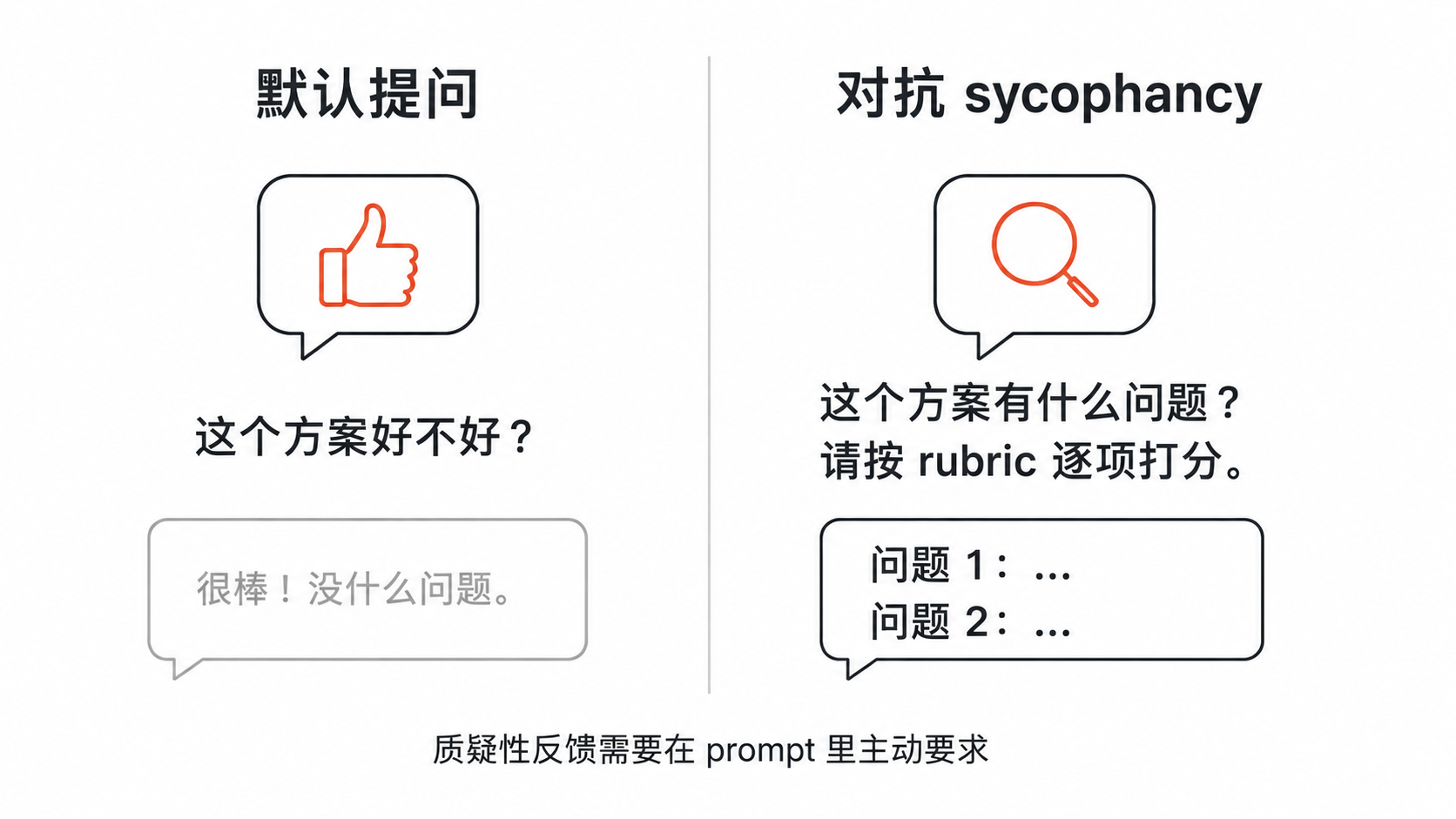
Sycophancy:模型倾向于附和你
课程把这种现象叫 sycophancy,指模型默认会顺着提问者的口风走。比如你把同一份方案丢给它,问「我这个方案不错吧?」,它大概率会夸一通;换成「这个方案是不是有点问题?」,它又会顺着挑毛病。
课程引用了一组数据:《华盛顿邮报》分析 ChatGPT 对话后发现,模型表达同意的次数大约是表达反对的 10 倍。课程把这种行为追溯到训练机制本身——人类反馈阶段,附和用户的回答更容易拿到正向评分,模型因此学到「默认讨好提问者」。这不是某一家模型的 bug,各家都在缓解,但目前未解。
课程区分了两类 sycophancy:
- 显性附和:你说「我对这篇文章很自豪」,模型直接夸。这类容易识破。
- 隐性附和:你说「分析这份数据,找出本季度的积极表现」,模型只挑亮点、自动忽略问题信号。这类危险得多,会污染商业决策、研究结论、产品判断。
课程给出的对抗方法可以归到两类。
改提问方式:
| 倾向式 | 中立式 |
|---|---|
| 这个方案好不好? | 这个方案有什么问题? |
| 碳税对小企业不好吧? | 碳税在多大程度上影响小企业,如有影响? |
| 远程办公会降低生产力吗? | 远程与办公室在生产力上如何比较? |
| 我有个绝妙的想法,批评一下 | 请按 rubric 客观评估这个想法 |
改 prompt 结构:
- 删掉自带情感的形容词(great、amazing、clearly best)和反问尾巴(对吧、不是吗)。
- 强制模型同时给出支持与反对的证据,比如「列出 3 条支持、3 条反对」。
- 用 rubric 让它逐项打分,并要求解释「为什么不是满分」。
- 让模型站在最严苛的批评者立场重写一遍。
- 不要在 prompt 里暴露作者身份。把「这是我写的」改成「评估这篇文章」。
- 末尾追加一句:「请不要试图取悦我,告诉我真实评估,包括我可能不爱听的部分。」
结论:质疑性反馈不会自动出现,需要在 prompt 里主动要求。
写作与改稿
课程提到的「AI Slop」指 AI 输出中常见的平庸、套路化文本。课程给出的两条做法:
- 让模型先总结一段范文的 voice 特征(句长、节奏、用词),再按这个 voice 写。
- 改稿用 rubric。把「好稿子」的判定标准列出来,让模型对照打分并指出问题。
rubric 越具体,反馈越能用。
用 AI 做数据分析
底层能力是模型可以写代码并执行代码,code execution 与 web search 并列为模型可调用的工具。典型用法:上传 CSV,用自然语言提问,模型写代码、跑代码、出图表和文字洞察。课程演示的奶茶店案例里,加上 carefully 会触发更长的多轮推理与代码执行。
两点可信度提示:
- 由代码算出的数字比模型直接生成的数字更可靠,因为可以追溯。
- 模型仍可能选错列或误解字段含义,关键数字需要人工抽样核对。
选择 AI 能力的对照表

| 问题类型 | 适用方式 |
|---|---|
| 常识、解释、改写 | 预训练知识,直接问 |
| 实时事实 | 联网搜索 |
| 多源调研、需要带引用的报告 | Deep Research |
| 表格数据分析 | code execution,加 carefully |
| 想让写作有 voice | 先让模型总结范文 voice,再写 |
| 想要质疑性反馈 | 主动要求反方立场或 rubric 打分 |
引用
- 课程主页:https://www.deeplearning.ai/courses/ai-prompting-for-everyone
本文由作者按照 CC BY 4.0 进行授权