让模型写脚本来调度模型:Claude Code 动态工作流详解
本文从头解释 Claude Code 的动态工作流,主要包含以下内容:
- 动态工作流(Dynamic Workflows)是什么,官方为什么做它;
- 它的主要 API 分别解决什么问题;
- 七种可复用的质量模式;
- 怎么配置和触发,运行时有哪些限制;
- 实际运行效果如何;
- 它和 Anthropic 几篇文章的关系;
- 基于它做的一个开源移植。
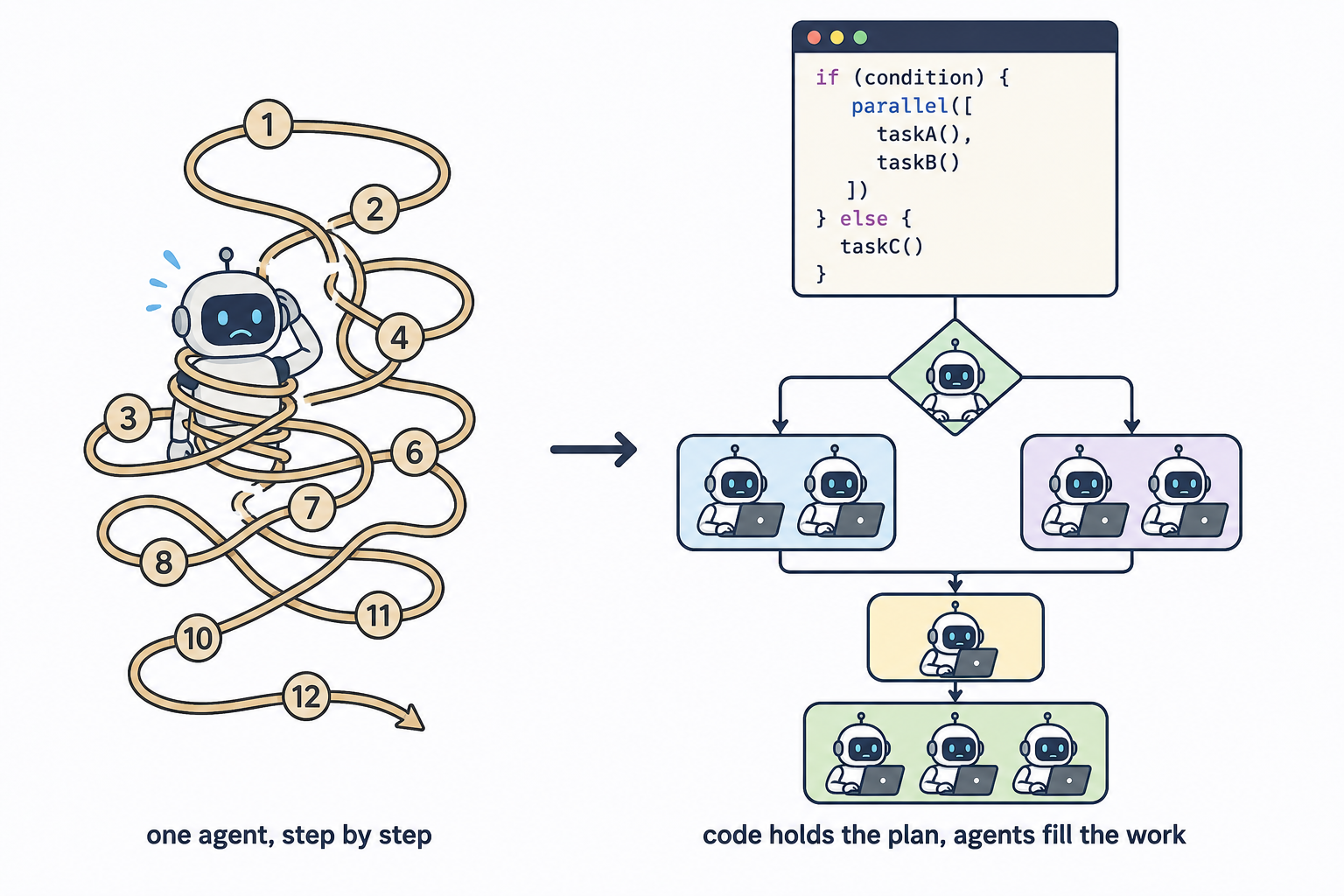
一、它要解决什么问题
如果你用过 AI 编程助手,大概熟悉这种工作方式:你提需求,模型一步步执行,每完成一步再决定下一步。这叫「智能体循环」(agent loop)——模型既负责执行,也负责调度。
在小任务中,这种方式通常可行。但官方对它瞄准的问题给了很克制的判断(原话翻译):
“有些问题对单个智能体的一次性处理来说太大了”——尤其是在”复杂的、有历史包袱的代码库”里。 (原文:”Some problems are too big for one pass by a single agent”,出自发布公告)
文档里给了更具体的「什么时候该用」(原话翻译):
“当一个任务需要的智能体多到一次对话协调不过来,或者你希望把调度逻辑固化成一段可以阅读、可以重跑的脚本时,就用工作流。”
它的应对思路,官方文档概括成一句话:
“工作流把计划搬进了代码”(A workflow moves the plan into code)。
具体说:你(或者模型本身)写一段普通的 JavaScript 脚本,脚本里规定好「哪些任务并行执行、哪些任务串行执行、循环几次、什么时候停止」;每个具体步骤——读代码、查资料、判断对错——交给一个独立的子模型(subagent)处理。
官方对它的完整定义是(原话翻译):
“动态工作流是一段 JavaScript 脚本,用来大规模调度子智能体。Claude 根据你描述的任务写出这段脚本,由一个运行时在后台执行,同时你的会话保持可响应。”
二、它和「子智能体」「技能」「智能体团队」有什么不同
Claude Code 里能做多步任务的机制不止一个。官方给过一张对照表,核心区别在于「谁持有计划」(who holds the plan):
| 子智能体 Subagents | 技能 Skills | 智能体团队 Agent teams | 工作流 Workflows | |
|---|---|---|---|---|
| 它是什么 | 模型派出的一个执行者 | 模型遵循的一段指令 | 一个主管协调的对等会话 | 运行时执行的一段脚本 |
| 谁决定下一步 | 模型,逐回合 | 模型,跟着指令 | 主管,逐回合 | 脚本 |
| 中间结果存在哪 | 模型上下文窗口 | 模型上下文窗口 | 共享任务列表 | 脚本变量 |
| 可复用的是什么 | 执行者的定义 | 那段指令 | 团队的定义 | 整套调度逻辑 |
| 规模 | 每回合几个 | 同子智能体 | 少数几个长期运行的会话 | 每次几十到几百个 |
| 被打断之后 | 重启这一回合 | 重启这一回合 | 其他会话继续运行 | 同一会话内可续跑 |
官方对这张表的解释(原话翻译):
“用子智能体、技能、智能体团队时,Claude 是调度者:它逐回合决定派谁、分配什么,每个结果都落在某个上下文窗口里。而工作流脚本自己持有循环、分支和中间结果,所以 Claude 的上下文最后只拿到最终答案。”
“把计划搬进代码,还让工作流能套用一种可复用的质量模式,而不只是多派几个智能体:它可以让独立的智能体在结论上报前互相对抗式评审,或者从几个角度起草方案再互相权衡,于是你得到一个比一次性处理更可信的结果。”
这两段是后面「质量模式」一节的官方依据。
三、它的核心 API(六个原语)
工作流脚本里能用的「原语」(基本构件)不多,但每一个都对应一个具体的工程问题。
来源说明(重要):下面这些函数名(
agent、parallel、pipeline等)和它们的精确签名,出自 Claude Code 工作流工具自带的规格说明——也就是 Anthropic 写给模型看的工具说明书,不是某篇公开博客。公开的工作流文档是写给最终用户的,故意没有列出这些函数签名。这一点文末「来源说明」里专门讲,并给出核实的方法。逐字原文见本节末尾。
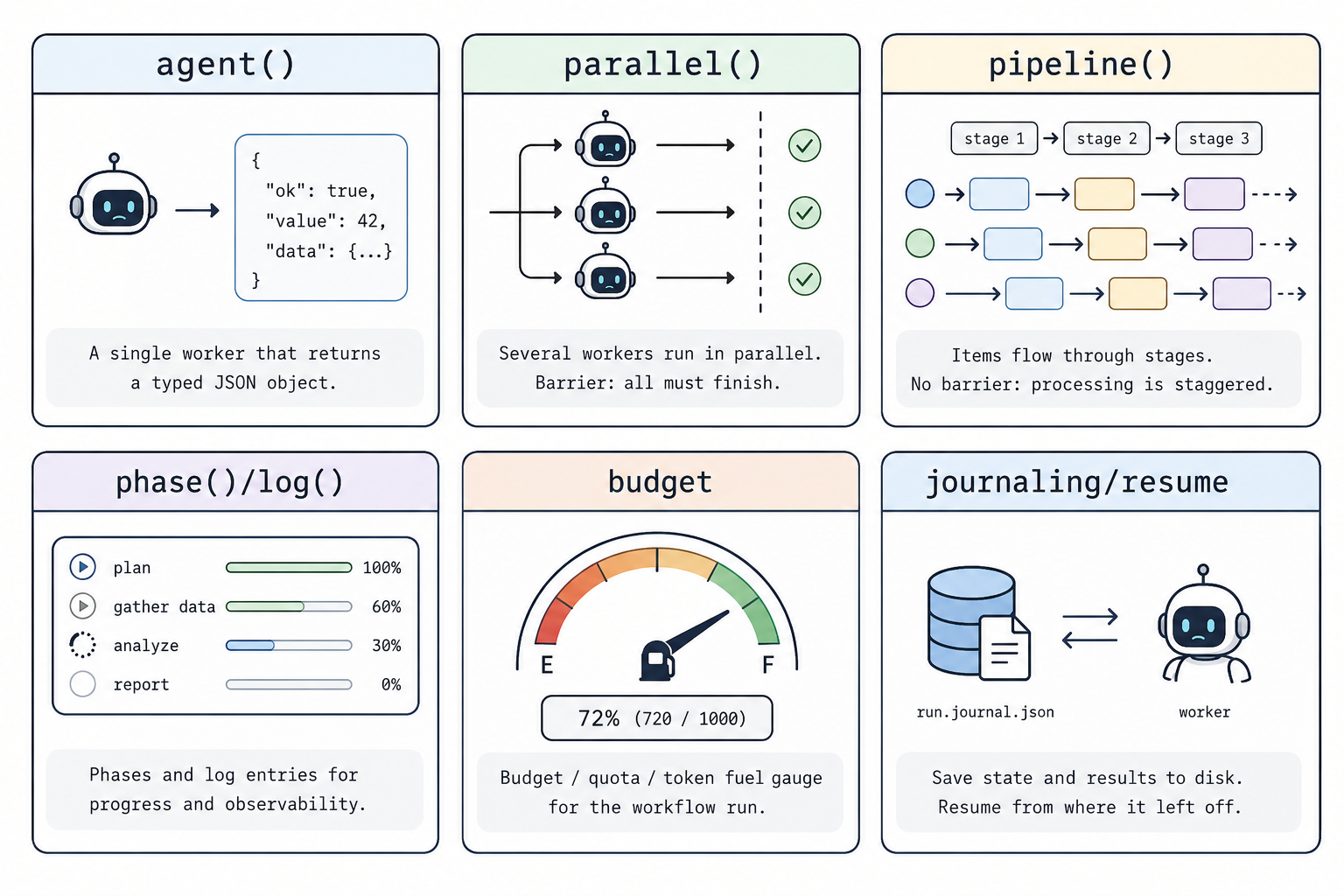
3.1 agent:带类型的模型调用
agent(prompt, { schema }) 用来派出一个子模型,给它独立的上下文窗口。
- 不带
schema:返回一段文本——你得自己解析,还可能解析失败。 - 带了
schema(一个 JSON Schema):工具层强制模型走结构化输出工具,不符合就让它重试,最后直接返回一个校验过的对象。
这样做的意义是:下游的去重、计数、过滤都可以交给确定性代码处理,不需要依赖脆弱的字符串解析。如果每一步的输出都是不可靠的文本,后续调度逻辑就很难稳定运行。
3.2 parallel / pipeline:并行与栅栏
parallel 和 pipeline 都用于并行执行任务,区别只有一处:要不要等所有任务都完成。
parallel(有栅栏):等全部 thunk 完成才返回。适合「需要全量结果」的场景——全局去重、投票计票、零结果就提前退出。pipeline(无栅栏):每个条目独立穿过所有阶段,阶段之间不互相等。条目 A 可能已经在第三阶段,条目 B 还在第一阶段。
为什么 pipeline 是默认选择?因为它的总耗时接近最慢的那条单独处理链路,而不是「每个阶段最慢任务」的耗时之和。如果每一阶段都设置栅栏,已经完成的条目会等待较慢的条目,整体效率会下降。只有当某个阶段确实需要前一阶段的跨条目信息(去重 / 计票 / 互相比较)时,才需要使用栅栏。
3.3 phase / log:运行过程可观测
phase("搜索") 标记当前阶段,log("...") 输出一行进度。它们不是装饰:有了这些信息,/workflows 进度面板才能按阶段分组,你也才能进入每个子模型查看提示词和结果。这对应 Anthropic 三原则里的透明性(transparency)。
3.4 budget:按预算控制执行规模
budget 提供 total、spent()、remaining()。两种用法:
- 静态:
const FLEET = total / 100k,按预算决定启动多少个模型; - 动态:
while (budget.remaining() > 50_000) { ... },运行过程中读取剩余预算。
预算用于限制是否继续启动新的 agent() 调用:达到预算后,后续调用会失败。需要注意的是,实际花费仍可能受并发中已启动、尚未结束的 agent 影响——也就是说,总花费可能超过预算线;超出幅度取决于并发数和已经启动的 agent 输出长度,最终以运行面板的统计为准。
3.5 journaling / resume:自动保存与续跑
每次 agent() 的结果都会被自动保存下来。在调用序列保持一致时,已完成的调用可以被复用;改了脚本之后,通常能复用最长的没变前缀,只有第一处改动以及之后的部分重新执行。这是它和「一次性执行」的重要区别:它是确定、可恢复的。
3.6 函数 API 原文
为了可追溯,把上面六个原语的精确签名逐字列出。下面这段英文原文来自工具规格里的 “Script body hooks” 段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- agent(prompt: string, opts?: {label?, phase?, schema?: object, model?,
effort?, isolation?: 'worktree', agentType?}): Promise<any>
Without schema, returns its final text as a string. With schema (a JSON
Schema), the subagent is forced to call a StructuredOutput tool and
agent() returns the validated object — no parsing needed. Returns null
if the user skips the agent mid-run or the subagent dies on a terminal
API error after retries (filter with .filter(Boolean)).
- pipeline(items, stage1, stage2, ...): Promise<any[]>
run each item through all stages independently, NO barrier between
stages. Item A can be in stage 3 while item B is still in stage 1.
This is the DEFAULT for multi-stage work.
- parallel(thunks: Array<() => Promise<any>>): Promise<any[]>
run tasks concurrently. This is a BARRIER: awaits all thunks before
returning. A thunk that throws resolves to `null` … .filter(Boolean).
- log(message: string): void — emit a progress message to the user
- phase(title: string): void — start a new phase; subsequent agent()
calls are grouped under this title
- args: any — the value passed as Workflow's `args`
- budget: {total: number|null, spent(): number, remaining(): number}
- workflow(nameOrRef, args?): Promise<any> — run another workflow inline
(注意:完整签名比常见的简化版多了 opts 全字段,以及 workflow() 内联调用——可以在一个工作流里再执行另一个工作流。)
3.7 内联调用与续跑细节
上面 3.6 的签名是脚本里直接能用的钩子。规格里还有几处更细的内容,多数解释材料(包括很多二手介绍)都没提到,这里补全。
① workflow(nameOrRef, args?)——在一个工作流里内联执行另一个工作流。 最后那行 workflow(nameOrRef, args?): Promise<any> 不只是「调用」,它支持把一个已保存的工作流或一段脚本引用当成子步骤执行,返回它的结果。这意味着工作流可以组合:你可以把「审计单个目录」写成一个工作流,再写一个外层工作流,对几十个目录分别内联调用它。至于内联工作流的资源怎么共享(是否共用并发上限、智能体计数、token 预算)、能不能多层嵌套,这些属于运行时的实现细节,以官方运行时的实际行为为准——本文不对这些约束下断言。
② resumeFromRunId——断点续跑的具体机制。 3.5 讲过「调用序列一致时可以复用已完成的调用」,这里说明它的实现方式。每次工作流运行都有一个运行号(runId),每个 agent() 调用的结果都按「调用序号 + 提示 + 选项」保存成一条记录。用 resumeFromRunId 重跑时:
- 没变的最长前缀——也就是从头开始、参数和上次完全一样的那一串
agent()调用——直接返回缓存结果,不再发请求; - 第一处改动的调用,以及它之后的全部调用,实时重新执行。
为什么是「最长未变前缀」而不是「全部命中」?因为每个 agent() 的缓存键里含调用序号(它在脚本里是第几个 agent())。脚本前半段没改,序号和内容都一样,命中;你在中间改了一句提示,从那一句起序号往后的内容都变了,于是从那里开始重新执行。这就是它「确定 + 可恢复」的底层——它不是把上次结果原样返回,而是逐调用、位置敏感地复用。
一个容易混淆的点:这种
resumeFromRunId是给「改了脚本后重新执行」用的(比如你调了某个提示词,想只重新执行改动部分,节省时间和 token)。它和前面 6.2 讲的「运行中途停掉再p续跑」是两回事——后者是同一个脚本被打断后恢复,前者是脚本本身被改动后的增量执行。
③ 一处需要更正的常见说法。 很多介绍(包括早期的一些笔记)会说「质量模式有 4 种」「函数签名就是 agent/parallel/pipeline/phase/log/budget 六个」。对照规格逐字核对后,这两点都不准确:
- 质量模式是 7 种,不是 4 种——常被漏掉的是
perspective-diverse verify(多视角验证)、loop-until-dry(直到没有新结果再停止)、no silent caps(不静默截断)。本文第四节已经补全这 7 种。 - 函数签名比六个多——
agent()有完整的opts字段(label / phase / schema / model / effort / isolation / agentType),还有workflow()内联调用、resumeFromRunId续跑。本文 3.6 + 3.7 给的是完整版。
把这条更正写出来,是因为它正好说明了「来源」为什么重要:这些细节只在工具规格里有,公开文档里没有,所以二手转述很容易丢失或讲错。
四、质量从哪来:七种可复用的模式
仅仅增加模型数量,并不会自动提高结果质量。动态工作流的关键在于:这些原语可以组合成可复用的质量模式。工具规格里逐字列了七种(它们是规格里命名的「常见形态」,不是 API 函数,需要脚本作者用原语组合出来)。
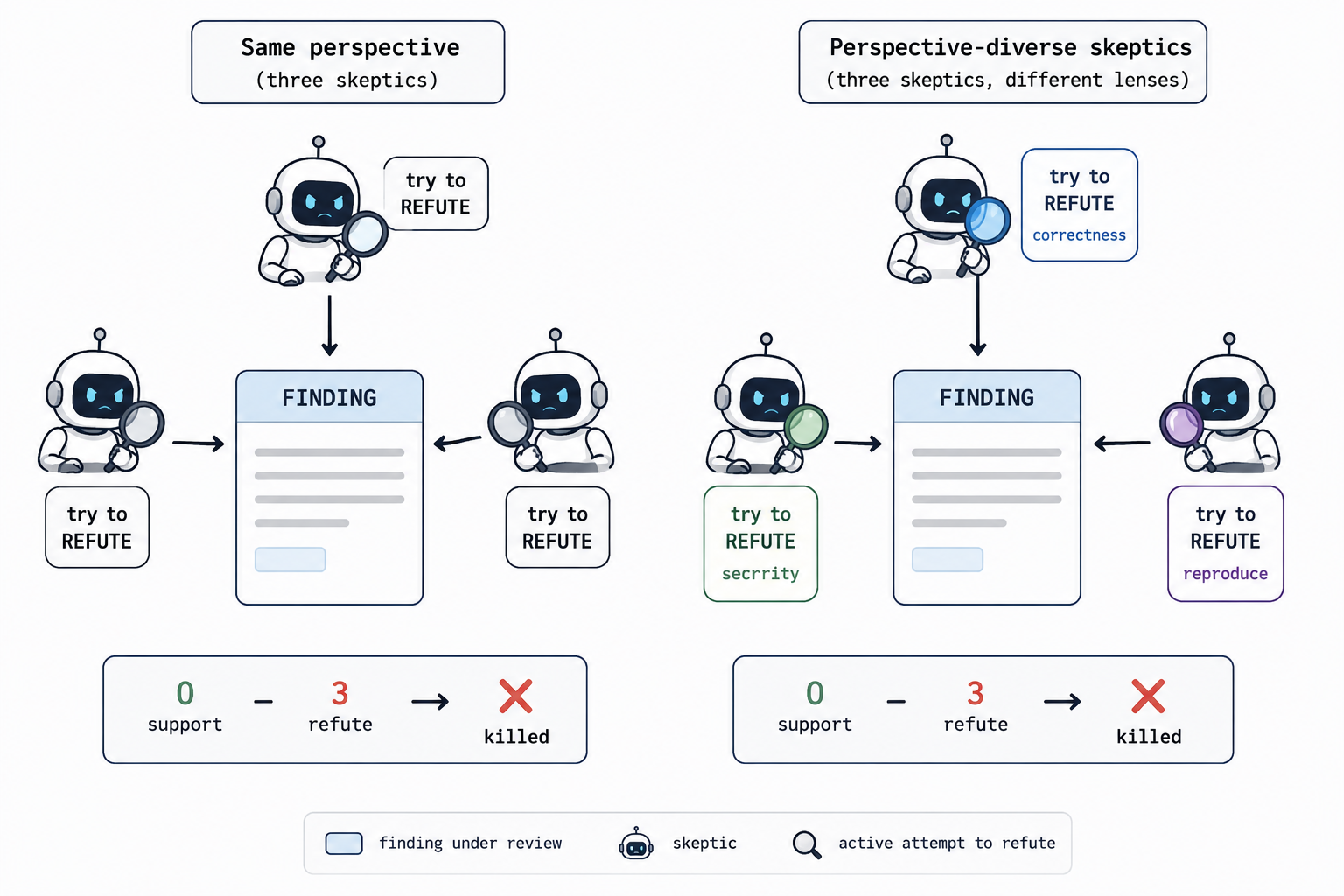
先说常被点名的 4 种:
1)对抗式验证(adversarial verify) 每个「发现」派 N 个独立怀疑者,提示词要求它们去反驳,多数反驳成功就丢弃。
- 为什么:过滤掉「看起来对、其实错」的结论。
- 和文章的关系:可视作《Building effective agents》里 evaluator-optimizer 的对抗式变体(属推断,原文未明说)。
2)评审团(judge panel) 从不同角度独立生成 N 个方案,并行打分,再基于得分最高的方案综合结果(也可以吸收其他方案中有价值的部分)。
- 为什么:可选方案很多时,多方案比较往往比「先生成一个方案再反复修改」更稳。
- 和文章的关系:对应 parallelization 里的 voting(同一个任务执行多次,获得多样输出)。
3)多角度普查(multi-modal sweep) 多个模型各用一种检索角度(按目录 / 按内容 / 按实体 / 按时间)并行搜索,彼此不共享中间结论。
- 为什么:单一检索角度容易遗漏信息。
- 和文章的关系:对应《Multi-agent Research System》里「主智能体派子智能体从不同角度并行调查」。
4)完整性批评者(completeness critic) 最后专门派一个模型检查「还缺什么——哪个角度没覆盖、哪条结论没验证、哪个来源没读」。它给出的缺口就是下一轮需要补充的任务。
- 和文章的关系:对应 evaluator-optimizer / 反思(reflection)。
另外 3 种(同样在规格里,常被忽略):
5)多视角验证(perspective-diverse verify) 当一个发现可能以多种方式出错时,给每个验证者一个不同的检查角度(正确性 / 安全 / 性能 / 能否复现),而不是派 N 个完全相同的验证者。多样化的检查角度更容易发现不同类型的问题。(它是对抗式验证的多视角版本。)
6)直到没有新结果再停止(loop-until-dry) 对规模未知的发现类任务(找 bug、找边界情况),连续 K 轮没有新结果才停止。简单地固定循环次数,容易漏掉后面才出现的问题。
7)不要静默截断(no silent caps) 如果工作流限制了覆盖面(只取前 N 个、不重试、抽样),就用 log() 把丢掉的东西说出来。否则「静默截断」会被误读成「全覆盖了」。
4.1 七种模式原文
下面是工具规格里 “Quality patterns” 段的逐字原文:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Quality patterns — common shapes; pick by task and compose freely:
- Adversarial verify: spawn N independent skeptics per finding, each
prompted to REFUTE. Kill if ≥majority refute.
- Perspective-diverse verify: give each verifier a distinct lens
(correctness, security, perf, does-it-reproduce).
- Judge panel: generate N independent attempts from different angles,
score with parallel judges, synthesize from the winner while grafting
the best ideas from runners-up.
- Loop-until-dry: keep spawning finders until K consecutive rounds
return nothing new.
- Multi-modal sweep: parallel agents each searching a different way
(by-container, by-content, by-entity, by-time).
- Completeness critic: a final agent that asks "what's missing — modality
not run, claim unverified, source unread?"
- No silent caps: if a workflow bounds coverage (top-N, no-retry,
sampling), log() what was dropped.
4.2 loop-until-dry 示例:用 seen 去重
工具规格里的示例把 loop-until-dry 和「对抗式验证」组合在一起:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
const seen = new Set(), confirmed = []
let dry = 0
while (dry < 2) { // 连续 2 轮无新发现才停
const found = (await parallel(FINDERS.map(f => () =>
agent(f.prompt, {phase: 'Find', schema: BUGS})))).filter(Boolean).flatMap(r => r.bugs)
const fresh = found.filter(b => !seen.has(key(b))) // 对照「所有见过的」去重
if (!fresh.length) { dry++; continue }
dry = 0; fresh.forEach(b => seen.add(key(b)))
const judged = await parallel(fresh.map(b => () =>
parallel(['correctness','security','repro'].map(lens => () => // 三个镜头各验一次
agent(`Judge "${b.desc}" via the ${lens} lens — real?`, {phase: 'Verify', schema: VERDICT})))
.then(vs => ({ b, real: vs.filter(Boolean).filter(v => v.real).length >= 2 }))))
confirmed.push(...judged.filter(v => v.real).map(v => v.b))
}
return confirmed
// 去重对照 seen,不是 confirmed —— 否则被评审否掉的发现每轮重新冒出来,循环永不收敛。
示例最后的注释是关键:去重要对照「所有见过的」(seen),而不是「验证通过的」(confirmed)。否则,被评审否掉的发现因为不在通过列表里,下一轮又会被当成「新发现」,循环可能一直无法结束。这行注释本就写在工具规格的示例里,不是杜撰的。
4.3 /deep-research 的工作流骨架
下面参照内置 /deep-research 工作流的真实脚本说明这些原语如何组合。脚本来自一次 /deep-research 运行后 Claude 自动保存在本地的文件(路径形如 ~/.claude/projects/<项目>/<会话>/workflows/scripts/deep-research-<runId>.js,约 350 行)。下面不是逐字摘录,而是按真实脚本结构重写的删节版伪代码:保留编排骨架,省略提示词正文、JSON Schema 定义和错误处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
// 阶段 0:拆解——把问题拆成 5 个搜索角度(结构化输出)
phase("Scope")
const scope = await agent(
`把这个研究问题拆成 5 个互补的搜索角度:${QUESTION} ...`,
{ label: "scope", schema: SCOPE_SCHEMA } // 返回 { angles: [...] }
)
// 阶段 1+2:pipeline——每个角度「搜索 → 去重 → 抓取」,阶段间无栅栏
const searchResults = await pipeline(
scope.angles,
// 第一段:按这个角度搜索
angle => agent(SEARCH_PROMPT(angle), { phase: "Search", schema: SEARCH_SCHEMA }),
// 第二段:URL 去重(纯代码,不耗模型)+ 受 fetchSlots 预算约束,再并行抓取
searchResult => {
const novel = searchResult.results.filter(r => !seen.has(normURL(r.url)) && fetchSlots-- > 0)
return parallel(novel.map(src => () =>
agent(FETCH_PROMPT(src), { phase: "Fetch", schema: EXTRACT_SCHEMA }) // 抽取若干 claim
))
}
)
// 阶段 3:Verify——每条 claim 派 3 个对抗式验证者投票
// 这里的栅栏是刻意的——claim 必须先全部汇齐、排序、取 top N,才能开始验证。
phase("Verify")
const voted = await parallel(
rankedClaims.map(claim => () =>
parallel( // 内层并行:同一条 claim 跑 3 票
Array.from({ length: 3 }, (_, v) => () =>
agent(VERIFY_PROMPT(claim, v), { phase: "Verify", schema: VERDICT_SCHEMA })
)
).then(verdicts => {
const refuted = verdicts.filter(Boolean).filter(v => v.refuted).length
return { claim, survives: refuted < 2 } // ≥2 票证伪就否决
})
)
)
const confirmed = voted.filter(v => v.survives)
// 阶段 4:综合——把通过验证的 claim 合成一份带引用的报告
phase("Synthesize")
return await agent(`把这些已验证的结论综合成报告:${confirmed}`, { schema: REPORT_SCHEMA })
这段骨架对应前文的几个机制:
- 它就是「五阶段」:Scope → Search → Fetch → Verify → Synthesize,每个
phase()对应进度面板上的一栏。 pipeline用在 Search→Fetch:某个角度搜完就立刻去抓取,不等其他角度——对应 3.2 讲的「无栅栏」。parallel用在 Verify,而且是刻意上栅栏:真实脚本里这里有一句注释——Barrier here is intentional(栅栏是故意的),因为所有 claim 必须先汇齐排序才能验证。这正是 3.2 说的「只有需要跨条目信息时才上栅栏」的真实例子。- 对抗式验证是嵌套 parallel:外层每条 claim 一个并行任务,内层每条 claim 再开 3 票并行——对应第四节第 1 种模式。
- 去重是纯代码(
seen/normURL),不消耗模型——因为上游schema保证了结构化输出,下游才能这样确定性处理。
完整脚本(含全部提示词和 Schema)可在 Claude 运行
/deep-research后用 View raw script 查看。本文这段是按真实结构删节的伪代码,便于阅读。
五、如何触发它
Claude Code 提供几种触发工作流的方式。
5.1 单次提问显式触发
在提示里加关键字 ultracode,或者直接用自然语言说「用一个工作流来……」(自然语言被当成同等的 opt-in)。例:
1
ultracode: 审计 src/routes/ 下每个 API 端点有没有漏掉鉴权检查
- 输入框里关键字会高亮,Claude 改成「写脚本」而不是逐回合做。
- 撤销高亮:macOS 按
Option+W,Windows/Linux 按Alt+W;或在高亮关键字后面直接退格。 - 彻底关掉触发:
/config里关 “Ultracode keyword trigger”。 - 版本差异:v2.1.160 之前字面触发词是
workflow,之后改成ultracode;自然语言两个版本都认。
5.2 当前会话启用自动编排
1
/effort ultracode
- Ultracode =
xhigh推理强度 + 自动工作流编排。开启后,每个实质性任务 Claude 都会自动判断是否需要使用工作流(一个请求可能拆成「理解代码 / 修改 / 验证」几个工作流依次执行)。 - 每个请求更费 token、更慢。
- 只持续当前会话,新会话会重置;回到常规任务时,可以用
/effort high调回去。 - 只在支持
xhigh的模型上有这个选项。
5.3 运行已有的工作流命令
- 内置:
/deep-research <问题> - 自己保存过的:
/<名字>
5.4 运行前要批准
每次运行会弹「计划预览」,列出将执行的阶段 + 选项:
- Yes, run it:开始运行
- Yes, and don’t ask again:以后对当前项目里的这个工作流不再询问
- View raw script:运行前先读脚本(
Ctrl+G用编辑器打开;Tab运行前还能改提示) - No:取消
是否弹这个框,取决于权限模式:
| 权限模式 | 何时提示 |
|---|---|
| Default / accept edits | 每次运行都问,除非选过 “don’t ask again” |
| Auto | 只第一次问;任何 Yes 记进设置,之后不问;ultracode 开着时完全跳过 |
Bypass permissions / claude -p / Agent SDK | 从不问,直接运行 |
一个容易忽略的点:权限模式只影响工作流启动时的确认。工作流派出的子智能体永远以
acceptEdits模式运行,文件编辑自动放行,并继承你的工具白名单。不在白名单里的 shell 命令 / 网页抓取 / MCP 工具,仍可能在运行中弹出权限确认——长时间运行前,最好先把需要用到的命令加进白名单。
5.5 保存复用与传参
得到满意结果后:/workflows → 选中那次运行 → 按 s 保存。两个位置(Tab 切换):
.claude/workflows/(项目内,clone 仓库的人都能用)~/.claude/workflows/(home 目录,所有项目可用、仅自己可见)
保存后变成 /<名字> 命令。保存的工作流可通过 args 接收输入,脚本里读全局 args——Claude 会把输入当结构化数据传进去,脚本可直接对它用数组/对象方法,无需自己解析。
六、它怎么运行,有哪些限制
- 运行时在与对话隔离的环境里执行脚本,中间结果留在脚本变量里,不进模型上下文。
- 每次运行都会把脚本保存到本地。路径形如
~/.claude/projects/<项目>/<会话>/workflows/scripts/<工作流名>-<runId>.js(例如deep-research-wf_432fa07b-d28.js)。Claude 启动时拿到这个路径——你可以让它给你,然后打开读、跟上次对比、改了再让它从改后版本重新执行。 - 运行时跟踪每个智能体的结果,这就是「同会话内可续跑」的底层支撑。
几条运行时强制的限制:
| 限制 | 原因 |
|---|---|
| 不能中途人工输入 | 只有权限提示能暂停;需要「阶段间签字」就把每个阶段拆成独立工作流 |
| 脚本本身不能碰文件系统/shell | 读写、运行命令都由子智能体完成;脚本只负责调度 |
| 最多 16 个并发(CPU 核少则更少) | 限制本机资源占用 |
| 单次运行最多 1000 个智能体 | 防止脚本因为循环错误而持续创建智能体 |
6.1 管理一次运行(/workflows 面板按键)
| 键 | 动作 |
|---|---|
↑ / ↓ | 选阶段或智能体 |
Enter / → | 进入阶段 / 智能体详情,看它的提示、最近的工具调用、结果 |
Esc | 退一层 |
p | 暂停 / 恢复整个运行 |
x | 停止选中智能体;焦点在运行上时停止整个工作流 |
r | 重启选中的运行中智能体 |
s | 把这次运行的脚本存成命令 |
6.2 续跑与成本
续跑:停止后可以恢复——已完成的智能体返回缓存结果,其余的实时执行。只在同一个会话内有效,退出 Claude Code 后,下个会话需要从头执行。
成本:一次运行会启动很多智能体,比在对话里做同一件事明显更费 token,并计入你套餐的用量和速率限制。官方建议先在小范围任务上试(单个目录、窄问题),/workflows 里能看每个智能体的实时 token,也可以随时停止,已完成的工作不会丢失。每个智能体默认使用你当前会话的模型,除非脚本给某个阶段指定别的模型。
七、配置要求与检查清单
7.1 环境要求
- 版本:Claude Code v2.1.154 或更高。
- 套餐:所有付费套餐可用。Max / Team / Enterprise 默认开启;Pro 用户需在
/config里手动打开 “Dynamic workflows”。 - 后端:Anthropic API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 都支持。
- 界面:CLI、桌面应用、IDE 扩展、
claude -p非交互模式、Agent SDK。 - 内置
/deep-research额外需要「网页搜索」工具可用。
7.2 前置检查清单
claude --version确认 ≥ v2.1.154。/config里确认 Dynamic workflows 开着(Pro 默认关)。- 想自动编排再开
/effort ultracode(可选,更费 token)。 - 想运行
/deep-research,确认网页搜索工具可用。 - 预先把智能体会用到的 shell 命令 / MCP 工具加进白名单,否则长时间运行时可能被权限确认打断。
/model确认当前模型(决定每个智能体的单价)。
7.3 如何关闭
/config关 Dynamic workflows(跨会话持久)。~/.claude/settings.json设"disableWorkflows": true。- 环境变量
CLAUDE_CODE_DISABLE_WORKFLOWS=1。 - 全组织关:managed settings 里设同一项,或 admin 后台开关。
- 关闭后:内置工作流命令不可用、
ultracode关键字不再触发、/effort菜单里也没有ultracode。
八、完整运行与验证
8.1 运行内置 /deep-research
1
/deep-research What changed in the Node.js permission model between v20 and v22?
- 运行:输入命令。
- 批准:弹框选 Yes。
- 看进度:
/workflows→ 方向键选这次运行 →Enter打开进度视图。能看到每个阶段的智能体数、token 总量、耗时;进入任一阶段可以查看每个智能体找到了什么。 - 读报告:运行完成后,报告会进入会话,带每条结论的来源引用,没通过交叉验证的结论已被过滤。
这个流程同时可以验证环境是否就绪:能弹出批准框、/workflows 有进度、最后生成报告,说明基本流程可用。
8.2 为具体任务生成工作流
1
ultracode: 审计 src/routes/ 下每个 API 端点有没有漏掉鉴权检查
- 关键字高亮后,Claude 写脚本而不是逐回合做。
- 批准框里点 View raw script 先读脚本,确认编排逻辑符合预期——这是验证「它到底要干什么」的关键一步。
- Yes 放行,
/workflows跟进度。 - 如果结果符合预期 → 选中 →
s存成命令复用。
8.3 验证与调试技巧
- 先用小范围任务验证:先运行一个目录 / 一个窄问题,确认产出正确、估算花费,再扩大到整个仓库。
- 读脚本:每次运行的脚本都会保存在本地,让 Claude 给你路径,打开读 / 对比 / 改完重新执行。
- 逐智能体检查:在
/workflows里进入单个智能体详情,看它的提示、工具调用、返回结果,方便定位问题。 - 停止与恢复:
x停止,已完成的工作不丢;p暂停后还能续跑。
九、实际效果:两个真实案例
9.1 官方案例:Bun 从 Zig 移植到 Rust
这是 Anthropic 发布公告里的案例。Bun 的作者 Jarred Sumner 用动态工作流,把 Bun 从 Zig 移植到 Rust:
- 约 75 万行 Rust 代码;
- 从第一个提交到合并,11 天;
- 现有测试 99.8% 通过;
- 用了数百个并行模型,每个文件配两个评审者。
他把几个工作流串起来:一个负责给每个结构体字段标注 Rust 的生命周期;一个用数百个模型写行为等价的移植代码、每个文件两个评审;一个「修复循环」让构建和测试通过;还有一个过夜运行的工作流删除多余拷贝并自动开 PR。(公告注明这个移植「尚未投入生产」。)
公告里有一句概括它瞄准的价值(原话翻译):
“原本你按季度规划的工作,现在几天就能完成。”
需要客观看待:这是产品公告的措辞,代表的是高投入场景,不是普遍体验。但这个案例本身(数字、过程)是具体可查的。
另一个客户反馈(来自 Klarna,公告引用):动态工作流「对大型代码库上的发现类和评审类任务特别有价值」,能发现静态分析没有发现的死代码。公告里 CyberAgent 的工程师把它的定位概括为:它「填补了『派出单个子智能体』和『搭建完整智能体团队』之间的空档」——也就是一个中间层。
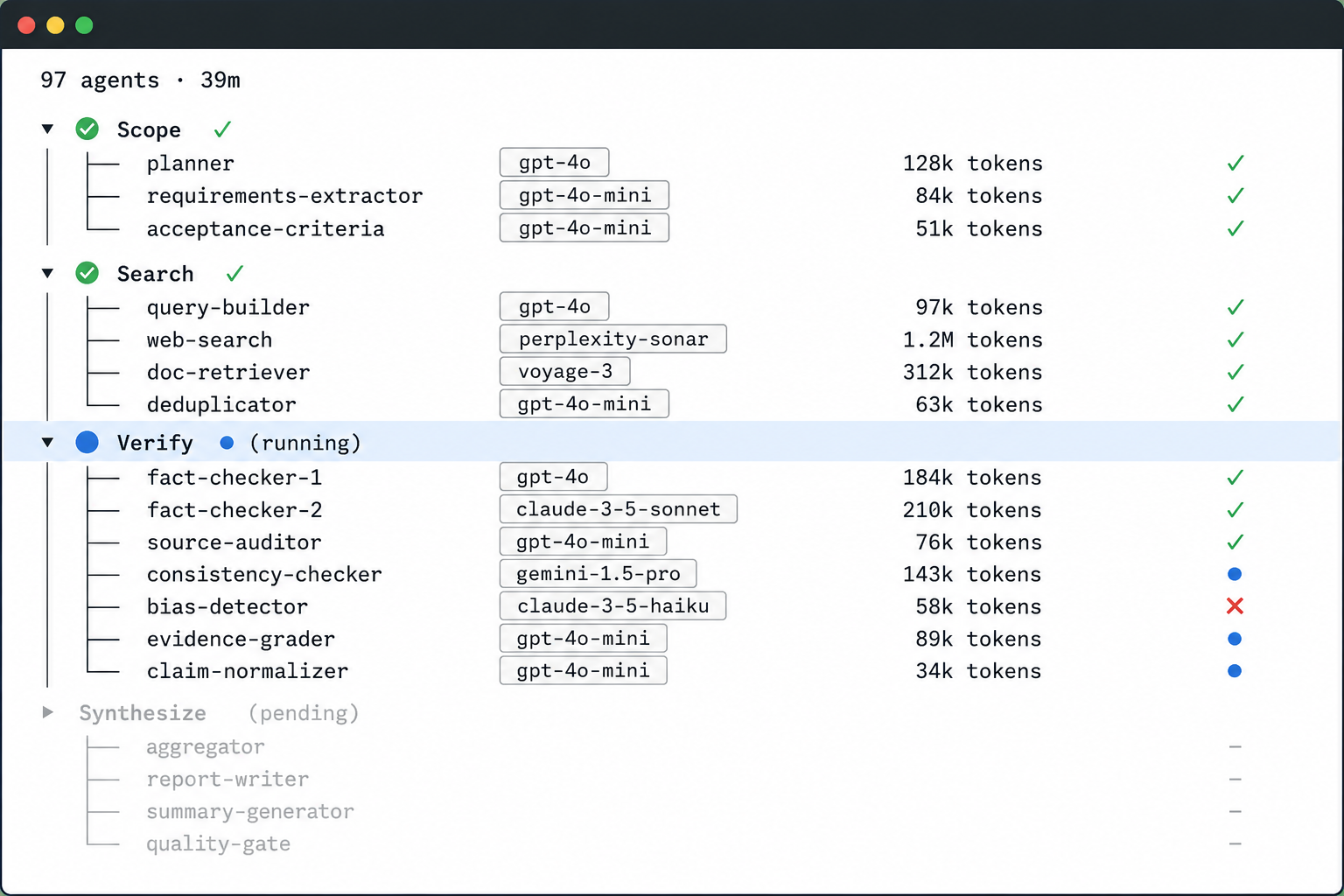
9.2 一次 /deep-research 实测
除官方案例外,我也用内置 /deep-research 实际运行了一次,问题是「对比 LangGraph、CrewAI、LlamaIndex Workflows 三个框架」。客观数据(运行号 wf_432fa07b-d28):
- 总共启动了 97 个模型,约 320 万 token,耗时约 39 分钟;
- 5 个搜索角度 → 获取 15 个来源 → 抽出 74 条结论 → 对其中 25 条做三票对抗验证;
- 最终 24 条通过、1 条被否决。
这次运行里有两个观察:
第一,调度是确定的。 启动的模型总数恰好等于脚本隐含的公式:1(拆解)+ 5(搜索)+ 15(抓取)+ 25×3(验证)+ 1(综合)= 97。不是模型临时决定的。这印证了「代码持有计划」。
第二,对抗验证过滤了一条错误结论。 其中一条听起来很合理的说法——「CrewAI 只有两种编排方式、没有原生的条件分支」——被三个独立验证者全票否决(0 支持 3 反驳),因为 CrewAI 的 Flows 确实有原生分支原语。如果没有这一步验证,这条错误结论就会进入最终报告。
这次运行也有一个限制:部分 WebSearch 返回了没有实际浏览内容的占位结果。最终报告主要靠 WebFetch 抓取官方文档和 gh api 直读源码来补足证据。因此,这次运行对「工作流机制」的验证比较充分;三框架选型结论仍应以各自最新官方文档为准。
十、它和 Anthropic 几篇工程文章的相似之处
说明:这两篇文章都可公开核实;但动态工作流与它们的对应关系,属事后对照,不是 Anthropic 的官方设计溯源。
这两篇 Anthropic 工程文章有助于理解动态工作流背后的工程思路。它们本身和动态工作流没有官方的因果关系,但讲的是同一类问题:
《Building effective agents》:文章里讲了五种模式——提示链(prompt chaining)、路由(routing)、并行化(parallelization)、编排者-工人(orchestrator-workers)、评估者-优化者(evaluator-optimizer),以及三条原则:保持简单(simplicity)、优先透明(transparency)、精心设计智能体与工具的接口(ACI)。这些都是文章原话。 动态工作流的原语(
parallel/pipeline/对抗式验证等)和这五种模式高度相似,但文章并没有逐条说「这个原语对应那个模式」。《How we built our multi-agent research system》:文章讲一个主智能体拆解任务、派多个子智能体并行调查、每个子智能体有独立上下文窗口当「智能过滤器」、运行时动态分解任务。动态工作流的
pipeline/parallel+ 结构化输出,和这套思路在结构上很相似。
十一、开源移植:pi-loom(一个 v0 最小版本)
理解了原理之后,我做了一件具体的事:在开源的 pi 智能体框架上,实现了这套动态工作流的一个最小版本(v0),开源为 pi-loom。需要先说明:这是一个移植的早期版本,核心原语和演示脚本已经完成基本验证,也在一个基于 pi 的宿主里做过端到端验证;但它和官方运行时不完全等价,部分语义仍在打磨。
如下截图是 pi-loom 的架构设计:
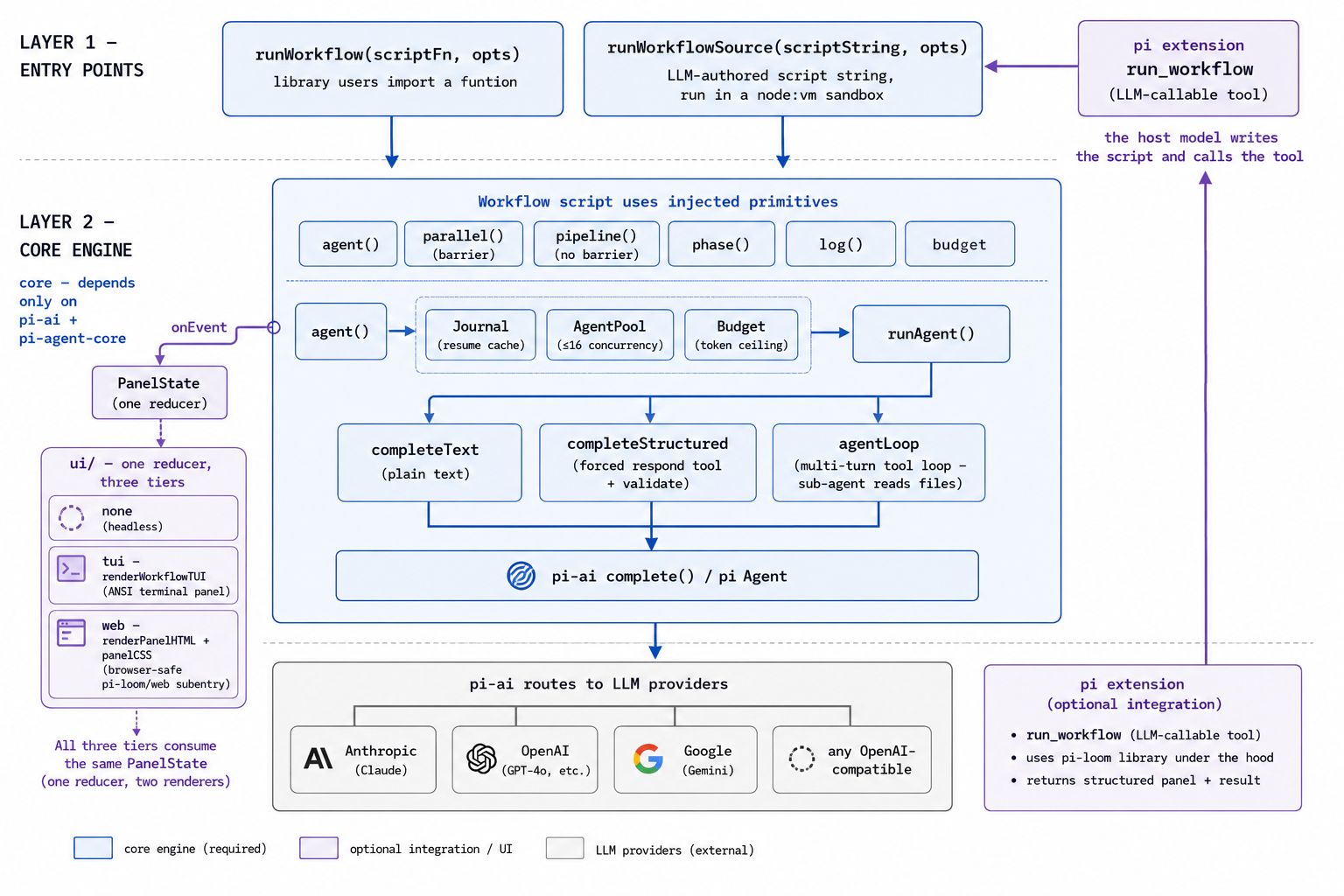
它的设计目标是:给已经在用 pi 搭建智能体的人,提供一个 run_workflow 工具——用户用自然语言说一句「用工作流审计一下这个仓库的鉴权」,由 pi 宿主的模型决定是否调用这个工具、生成调度脚本,再由引擎执行。这个路径已经在一个基于 pi 的宿主里完成过一次端到端验证:宿主模型自主调用了 run_workflow,派出的子智能体真实读取了代码,进度面板按阶段实时渲染。但这只是单个宿主上的验证,不代表已经打磨成熟的产品路径。
目前实现了:
agent/parallel/pipeline/phase/log/budget这套原语;- 基于 JSON Schema 的结构化输出(注意:当前版本里「结构化输出」和「让子智能体带工具读文件」这两条路径还不能组合,是已知的边界);
- 断点续跑(也有未覆盖的边界情况);
- 一套对照官方进度面板的进度 UI:把运行事件归约成一份面板状态,再渲染成终端界面或网页界面(两者同构)——运行开始时列出所有阶段,每个阶段下面显示它派出的子智能体,完成后标记为完成;
- 脚本在
node:vm沙箱里执行,解析阶段静态拦截Date.now()、Math.random()这类破坏可复现性的调用。这个沙箱的目的是限制误用、提高可复现性,不是安全边界——脚本本来就由宿主自己的模型生成、在宿主进程里执行,静态检查也仍有绕过的可能。
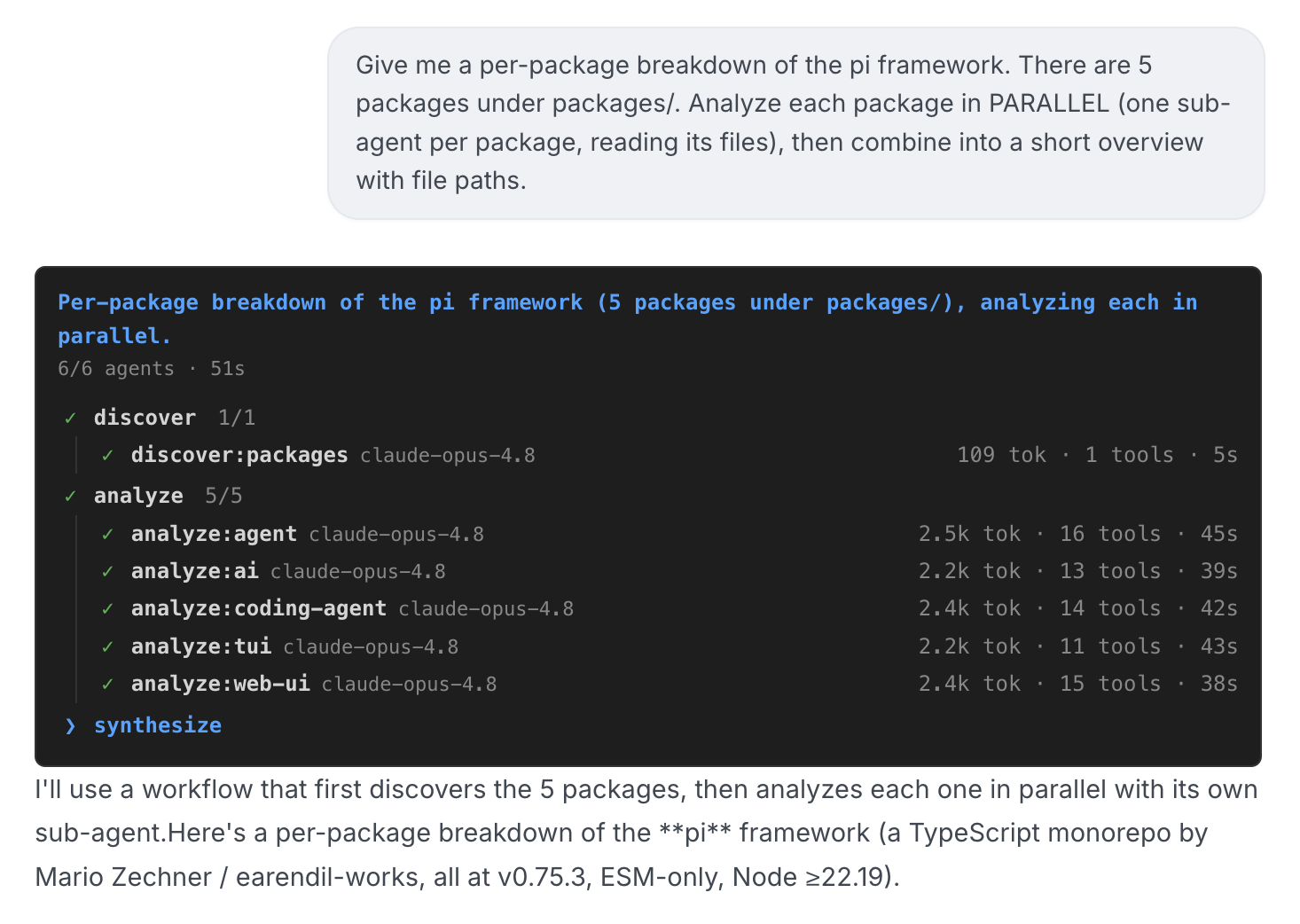
如上面截图,是在一个基于 pi 的宿主里真实跑出来的网页面板:所有阶段列成一棵树,某个阶段下面五个子智能体并行展开,各带模型名、token 和耗时。
这部分是基于 pi 的工程实现,不代表官方,也还没到「完整复刻」的程度。 开源出来,是希望用 pi 的人能在此基础上继续完善。
仓库地址:https://github.com/betaHi/pi-loom
结语
动态工作流的核心,可以归结成官方那句话:「把计划搬进代码」。它不是要取代智能体循环,而是为「单个智能体一次处理不完的大任务」提供一种更可复现、更可扩展的结构。
它适合的场景官方说得很明确:代码库级的审计、跨大量文件的迁移、需要多方交叉验证的研究。它的代价也很明确:更费 token、更慢,也需要提前想清楚任务怎么拆分。
实践上,可以先完整运行一次 /deep-research 建立直觉,再读 anthropic-cookbook 里的五种模式;之后选 LangGraph 或 LlamaIndex Workflows 运行一个小例子。要自己实现类似能力,可以用 Agent SDK(或我的 pi-loom)加一层编排。
参考文章
- 发布公告
- 工作流文档(总览 / 触发 / 运行机制)
- 创建自定义子智能体
- 《Building effective agents》
- 《How we built our multi-agent research system》
关于「工具规格」这个特殊来源:本文的函数签名(3.6 节)和七种质量模式逐字原文(4.1 节),出自 Claude Code 工作流工具自带的规格说明——也就是工具交给模型时附带的、给模型看的说明书(model-facing instructions),既不是实现源码,也不是公开文档。
- 局限:这段说明书公开渠道看不到,无法逐字核验原文。
- 能做的间接验证:在 Claude 写工作流时点 View raw script,或读它保存在本地的脚本文件(路径形如
~/.claude/projects/<项目>/<会话>/workflows/scripts/<工作流名>-<runId>.js),看它实际用了哪些函数、怎么用——这能印证 API 的形态,但不能证明说明书的逐字措辞。
所以本文这部分请当作「基于工具规格的转述」,而非可一键核验的公开文档。