Agent 为什么一到执行阶段就容易失控
这篇文章想单独讨论一个更具体的问题:
一个 Agent 处理到第 50 个文件时,突然开始自己写脚本批量操作——你会不会第一反应觉得它变聪明了?其实它已经开始失控了。
如果只看表面,今天关于 Agent 的讨论很容易落到 prompt、模型能力和工具数量上。但把几份材料连在一起看,再对照一次真实工程复盘,问题会变得更具体一些:为什么需求更清楚了、工具更多了、上下文也更长了,Agent 在执行阶段还是经常失控?
最近重新看 Karpathy 的 autoresearch、AutoResearchClaw,再回头看自己一个项目里,多文件处理,经过了一周迭代、8 次以上生产运行,线索逐渐收拢到同一个方向上。Agent 的难点,可能已经不只是”怎么生成”,而是”怎么稳定地跑”。
把问题压缩一点看,线索大致可以收成四点。
1. autoresearch 讲清了什么是最小闭环
autoresearch 的价值,不只是它很火,而是它把问题压得很小,于是关键结构变得很清楚。
README 里有一句话,几乎可以当作整个项目的摘要:
“The idea: give an AI agent a small but real LLM training setup and let it experiment autonomously overnight.”
它的结构也非常克制,核心就三样东西:
1
2
3
prepare.py 固定基础设施,不改
train.py Agent 唯一修改的文件
program.md 人写的方向、目标和约束
再加上一条非常重要的约束:固定 5 分钟时间预算。
“Single file to modify. Fixed time budget.”
如果把它翻成最容易理解的话,其实就是这样一个循环:
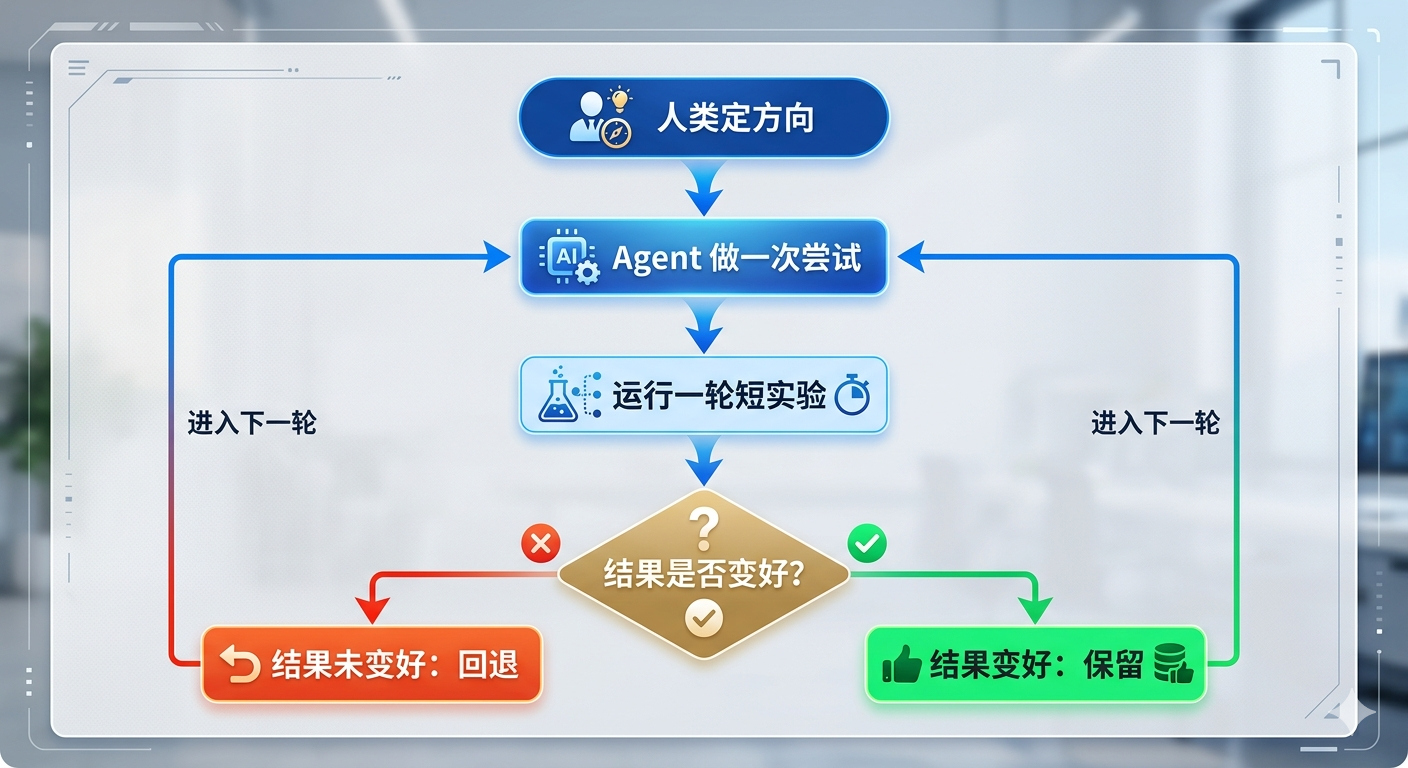
这个结构看起来其实很简单,它的重点不在”生成一次答案”,而在”能不能连续试错、连续比较、连续修正”。从这个角度看,Agent 工程化更像是在设计 loop,而不只是设计一次回答。
Anthropic 在 context engineering 那篇文章里给了一个很简洁的定义,也指向同一个方向:
“We’ve gravitated towards a simple definition for agents: LLMs autonomously using tools in a loop.”
如果没有 loop,很多系统可能还谈不上真正意义上的 Agent。
2. 真正的问题,不只是有没有 loop,而是谁在控制它
只有闭环,还不够。
在真实任务里,一个系统即便已经有了”行动 - 观测 - 反馈”的结构,也还是可能很快失控:
- 模型会自己扩大任务范围,从单文件变成批量处理
- 会自己发明 checkpoint 格式,用自造的字段名替代约定好的 schema
- 会在上下文变长后突然开始走捷径——写一段 Python 脚本全局修改,把约定好的文件标记全部抹掉
表面上看它还在持续工作,实际上过程已经偏掉了。
Anthropic 在 harness 一文中把这种现象叫做 context anxiety——模型”感觉到”快接近上下文限制,就开始提前草草收尾。
在我们的项目里也观察到了完全一致的行为:Agent 处理多个文件,到第 50 个文件左右时,会开始尝试写脚本批量处理剩余文件,或者派生子 Agent 试图并行化。不是它不知道规则,而是上下文压力大到一定程度后,它会自行发明”效率更高”的绕过方式。
这次复盘里比较明确的一点是,尽量不要让 LLM 管流程,而是让它只做局部判断。流程控制、状态管理、停止条件、失败分流,这些部分如果也交给模型,整体稳定性往往会迅速下降。
后来相对稳定下来的做法反而很朴素:
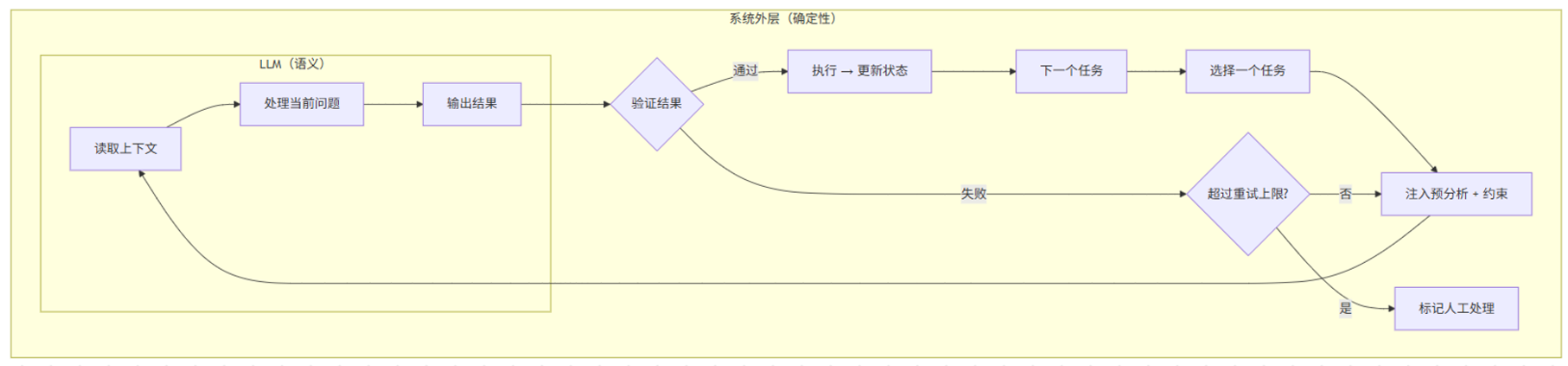
LLM 变成了一个接近”纯函数”的角色。输入是问题和上下文,输出是结果;状态管理、循环控制、异常处理,都放回系统外层。
不过,让 LLM 只做局部判断,不代表给它的信息也是局部的。相反,服务端可以在每次调用前做一轮预分析——比如自动检测哪些文件发生了大规模重构、哪些已经被删除、哪些存在高风险——把 LLM 自己发现不了的上下文提前注入进去。模型的职责变窄了,但拿到的信息反而更精准了。
纯函数要跑得好,输入端也得被系统精心准备。
同一篇文章里也在处理类似问题。他们的方案是三个 Agent 分工——Planner 定义规格、Generator 按 Sprint 实现、Evaluator 用 Playwright 像真实用户一样测试打分。核心思路一致:问题往往不只是”有没有 loop”,而是”这个 loop 有没有被工程系统接住”。
3. 这次最有用的变化,不是 prompt,而是脚本前置
如果只让我保留一条最具体的工程结论,那大概会是这一条:很多问题根本不该留在 loop 里让 LLM 处理。
这次最明显的变化,不是 prompt 又补了几条,也不是 loop 写得更精细了,而是把一批结构稳定、规则明确、可以确定性处理的文件,直接从 LLM 手里拿走,交给脚本先处理。
这部分在复盘里的数据很直接:
1
2
3
4
5
纯 LLM:13.3 小时,质量 77%
脚本 + LLM:4.5 小时,质量 96%
从 LLM 工作负载里移出:80 个文件
注解错误:23 个文件 → 0 个文件
这背后不是某个技巧,而是一条边界。机械问题尽量交给脚本,语义问题再交给 LLM。写成更工程一点的话,就是两阶段架构:

这条边界一旦清楚,整个系统会轻很多。LLM 不再被机械劳动拖住,loop 也不再被大量本可确定性解决的问题消耗掉。
这里还有一个容易忽略的细节:脚本阶段内部的分发顺序也是有讲究的。先处理最确定的(直接删除、直接跳过),再处理格式固定的(如配置文件),最后才是需要部分判断的(半结构化的局部修复)。每一层都比下一层更快、更确定,确保没有文件会在更快的方法可用时被更慢的方法处理。顺序本身就是一种工程决策。
作为对比,prompt 层面的优化并不是没用,但收益递减非常明显:
两个最大的改进都不是 prompt 变更——它们是架构变更。很多时候,真正的提升并不来自把模型调得更强,而来自把一部分工作从模型那里收回来。
4. 放在一起看,真正重要的是四条边界
如果把 autoresearch、AutoResearchClaw、Anthropic 几篇文章,再加上这次复盘放在一起看,最后留下来的其实不是一个更复杂的框架,而是几条更清楚的边界。
第一条:机械问题和语义问题的边界
机械问题尽量交给脚本,语义问题再交给 LLM。边界一旦不清楚,模型就会被大量本可确定性解决的任务拖住。上面第 3 节的数据已经说得很直白了。很多 Agent 工程的进展,某种程度上都可以用一句话来描述:团队有没有持续把”已经被理解清楚的问题”从 LLM 区迁移到脚本区。
第二条:生成和评估的边界
让同一个实体既负责产出结果,又负责批准自己的结果,通常会越来越乐观。harness 一文中有一句原话很直接:
“Out of the box, Claude is a poor QA agent. I watched it identify genuine issues, then talk itself into believing they weren’t important, and ultimately approve the work.”
在我们的项目里也观察到类似的现象。把 LLM 输出和人工修复逐文件对比,第一眼看到 111 个文件有问题,直觉反应是”质量太差”。但根因分析之后发现:
- 11 个是 LLM 更正确(它比人类更严格地执行了既定规则)
- 6 个是功能等价的重写
- 6 个是人工修复时额外新增的代码(原本并不存在)
零实际代码丢失。最大的”差异”反而是 LLM 比人类更忠实地执行了既定策略。
所以验证器的设计往往比直觉里更难。很多表面上的”差异”并不一定是真错误;一旦代码本身发生变化,依赖静态计数、固定标记或简单规则的校验方式,就很容易产生误报。更稳妥的做法,通常不是把规则写得更死,而是让验证逻辑能理解变化发生的上下文,区分”异常丢失”和”合理消失”。从这个意义上说,validator 本身也是一个需要持续迭代的系统,而不是一次性写完的检查脚本。
第三条:短期上下文和长期经验的边界
不是所有信息都应该留在当前上下文里,也不是所有教训都该靠下一轮临场回忆。checkpoint 解决的是当前过程别丢,memory 解决的是同样的错误别再犯。
这一点 AutoResearchClaw 做得更完整。它的 MetaClaw 机制在每次运行后提取经验教训,带 30 天时间衰减,下次运行自动注入 prompt。受控 A/B 实验数据显示:启用后阶段重试率下降 24.8%,优化周期数减少 40%,鲁棒性评分提升 18.3%。
前面提到的 context engineering 文章则从另一个角度讲了同一件事:上下文不是越多越好,而是有限注意力预算里的高信号编排。他们提出的 attention budget 概念——每引入一个新 token 都在消耗这个预算——意味着塞进去的信息如果不是高信号的,反而会稀释模型的注意力。压缩、笔记、子 Agent 架构,本质上都是在管理这个预算。
第四条:Agent 自主性和系统约束的边界
这是最反直觉的一条,也是我花了最久才接受的。
一开始很自然的想法是:prompt 写清楚规则,模型就会遵守。于是我们写了 14 条 ABSOLUTE PROHIBITIONS——禁止批处理、禁止写脚本、禁止派生子 Agent……
全部无效。Agent 每隔几次运行就会违反。
最终真正解决问题的是一行 CLI 配置:
1
--disallowedTools Agent,TaskCreate,TaskUpdate,TaskGet,TaskList,EnterPlanMode
在 CLI 层面直接禁掉工具。Agent 想派生子 Agent?工具不存在。想创建任务列表搞批处理?工具不存在。从 v8 开始,零违规。
再配合每轮 10 个文件的硬预算(MAX_FILES_THIS_SPAWN),解决了 Agent 在上下文增长后行为退化的问题。之前有一次单个文件卡死了 7860 秒(超过两小时),加了 10 分钟 stall detection 之后自动杀掉重启,这类问题也消失了。
一行 CLI > 14 条自然语言禁令。预算硬限制 > “请注意控制资源”。超时强杀 > “请在合适的时候停下来”。
这也解释了为什么可观测性在 Agent 工程里不是可选项。4 个多小时的运行,没有实时日志和进度指标,你甚至不知道它是在做对的事情、做错的事情,还是已经悄悄卡死了。我们最终构建了:
- WebSocket 实时日志
- 5 秒刷新的仪表盘
- 每个文件标注
resolvedBy: 'script' | 'llm'的追溯机制
只有被观测到的结果,才能被反馈;只有被反馈的结果,才能进入下一轮决策。
能靠系统约束解决的问题,最好不要留给模型自觉。
结尾
如果一定要把这段时间的体会压成一句话,大概可以写成:Agent 的上限当然取决于模型,但它的可用性越来越取决于工程。
模型负责给出候选解,系统负责约束、验证、调度、记录和复盘。前者决定能不能偶尔跑出很亮眼的结果,后者决定能不能比较稳定地交付。
接下来更值得继续看的,可能还是这几件事:
- loop 能不能被设计成真正可观测、可反馈、可纠偏的闭环
- 机械任务还能不能继续从模型里剥离出来
- 经验和评估能不能沉淀成系统能力
另外一个我越来越觉得被低估的方向是工具设计——Anthropic 在 writing tools for agents 一文中有一个说法很好:工具不只是 API 的薄封装,它更像是 Agent 的认知接口,会直接塑造 Agent 的行动路径。这个话题值得单独展开。
如果 Agent 真的会从”能玩”逐步走向”能用”,分水岭多半不在下一条更强的 prompt 上,而在这些工程细节什么时候开始变成默认配置。
参考文档
- karpathy/autoresearch
- aiming-lab/AutoResearchClaw
- Anthropic - Harness design for long-running apps
- Anthropic - Effective context engineering for AI agents
- Anthropic - Writing tools for agents
- Anthropic - Demystifying evals for AI agents
附录:架构图 mermaid 源码
复制到 mermaid.live 可直接生成图片:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
flowchart TD
subgraph 系统外层["系统外层(确定性)"]
A[选择一个任务] --> B[注入预分析 + 约束]
B --> C
subgraph LLM["LLM(语义)"]
C[读取上下文] --> D[处理当前问题] --> E[输出结果]
end
E --> F{验证结果}
F -->|通过| G[执行 → 更新状态]
G --> H[下一个任务]
H --> A
F -->|失败| I{超过重试上限?}
I -->|否| B
I -->|是| J[标记人工处理]
end